
Casper is a compiler that can automatically retarget sequential Java programs to Big Data processing frameworks such as Spark, Hadoop or Flink.
Learn More Online Demo GitHub Mailing List
Abstract
MapReduce is a popular programming paradigm for developing large-scale, data-intensive computation. Many frameworks that implement this paradigm have recently been developed. To leverage these frameworks, however, developers must become familiar with their APIs and rewrite existing code. Casper is a new tool that automatically translates sequential Java programs into the MapReduce paradigm. Casper identifies potential code fragments to rewrite and translates them in two steps: (1) Casper uses program synthesis to search for a program summary (i.e., a functional specification) of each code fragment. The summary is expressed using a high-level intermediate language resembling the MapReduce paradigm and verified to be semantically equivalent to the original using a theorem prover. (2) Casper generates executable code from the summary, using either the Hadoop, Spark, or Flink API. We evaluated Casper by automatically converting real-world, sequential Java benchmarks to MapReduce. The resulting benchmarks perform up to 48.2x faster compared to the original.
Legacy Applications and Changing Demands





Big Data Processing Frameworks can help!


Process Large Volumes of Data
Scalable and Fault Tolerant
Optimized Parallel Execution
Inertia to Adapting New Technology




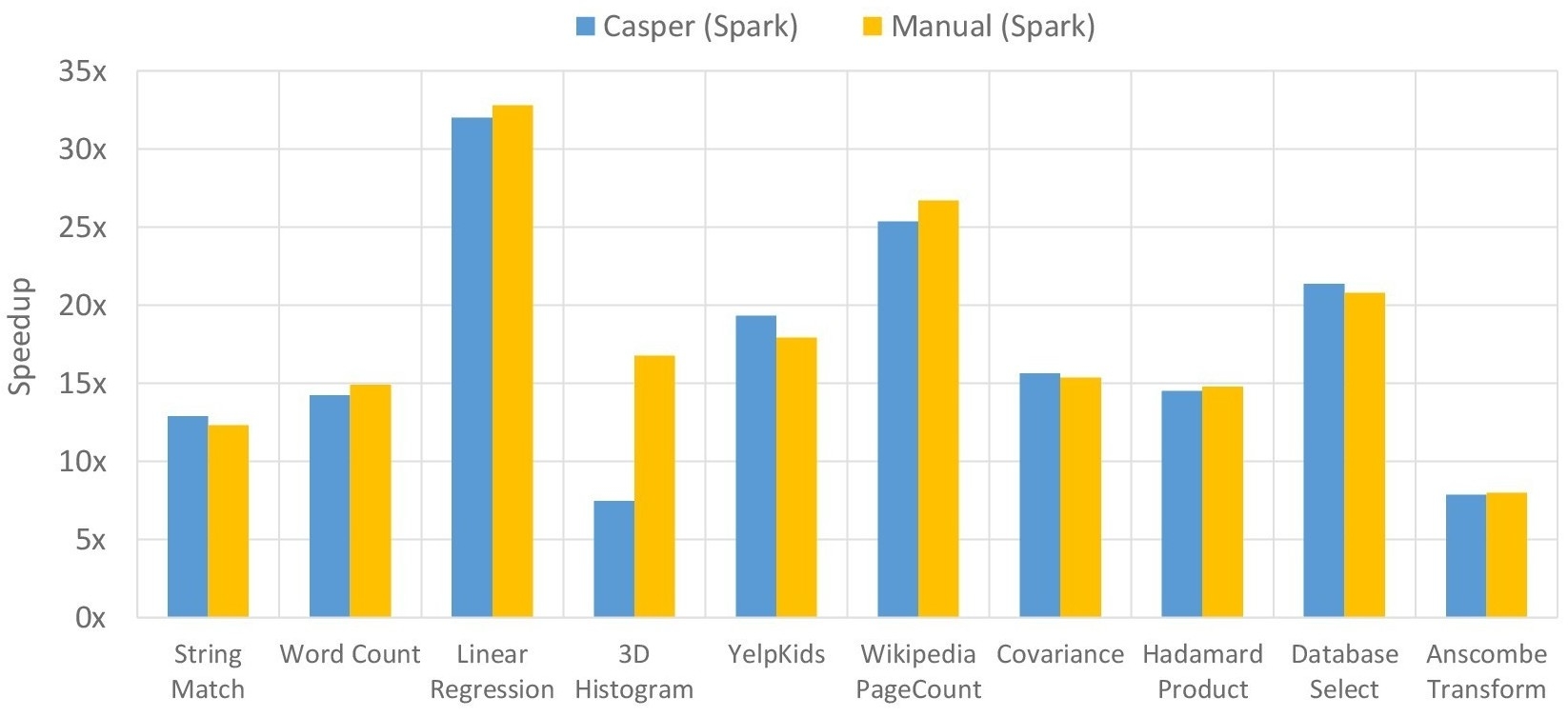
Performance Comparison: Casper vs Manual (75GB, 10 Nodes)
Publications
[1] Automatically Leveraging MapReduce Frameworks for Data-Intensive Applications
Maaz Bin Safeer Ahmad and Alvin Cheung
SIGMOD 2018
[2] Optimizing Data-Intensive Applications Automatically By Leveraging Parallel Data Processing Frameworks
Maaz Bin Safeer Ahmad and Alvin Cheung
SIGMOD 2017 Demo
Honorable Mention for Best Demo Award
[3] Leveraging Parallel Data Processing Frameworks with Verified Lifting
Maaz Bin Safeer Ahmad and Alvin Cheung
SYNT 2016 – Presentation Slides
Best Student Paper Award
Sponsors








Affiliations


